
好的,以下是一个简单的 Python 代码示例,用于从给定的 URL 中提取头部公共信息,类似于知识星球 Markdown 文档内链接的信息提取:
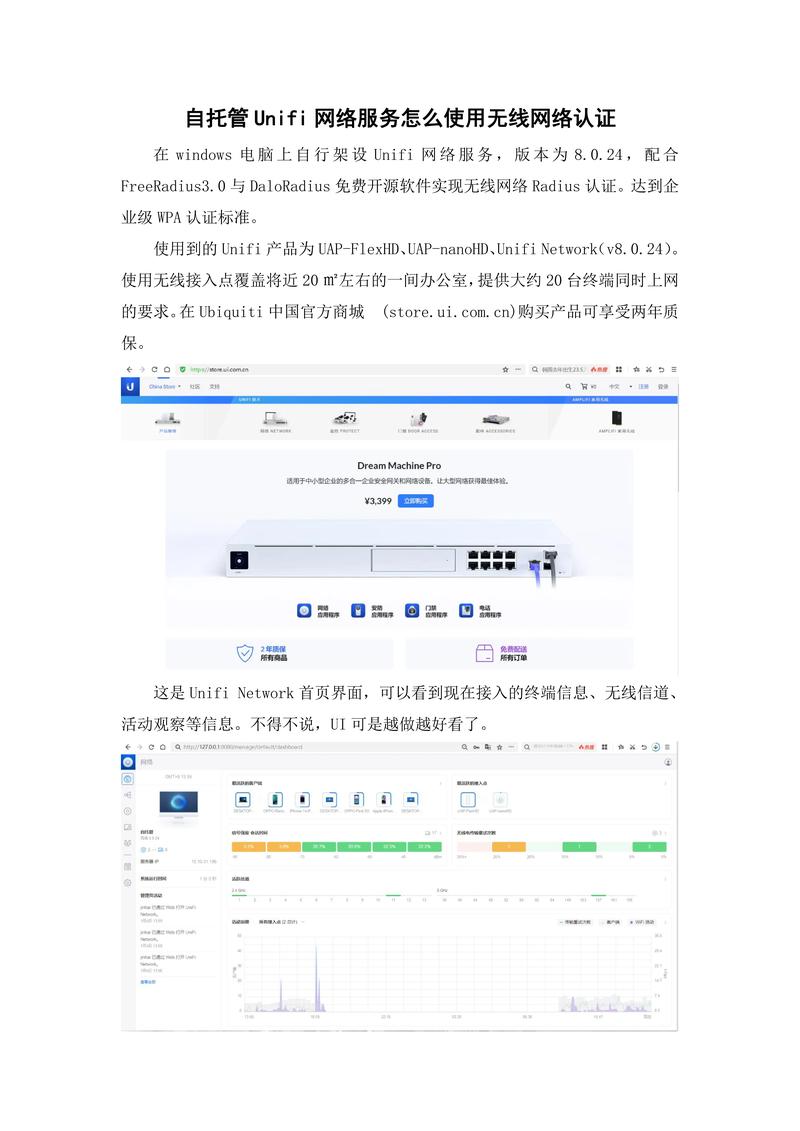
“`python
import requests
from bs4 import BeautifulSoup
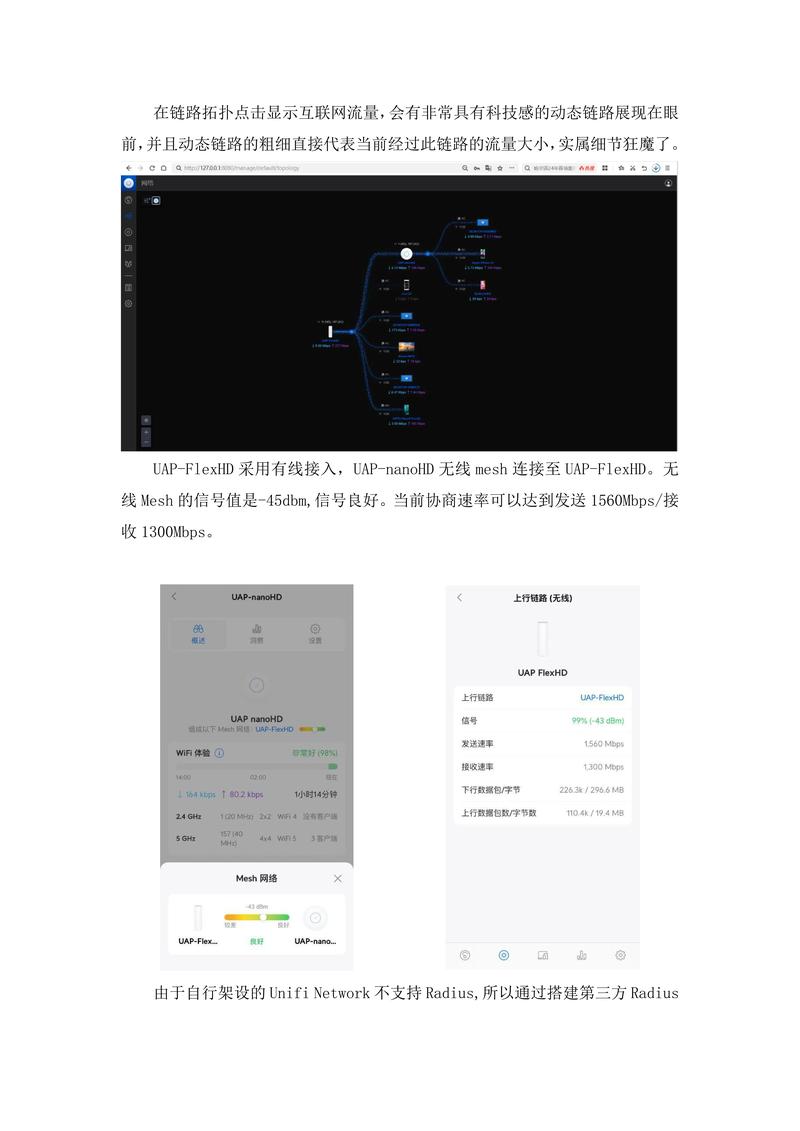
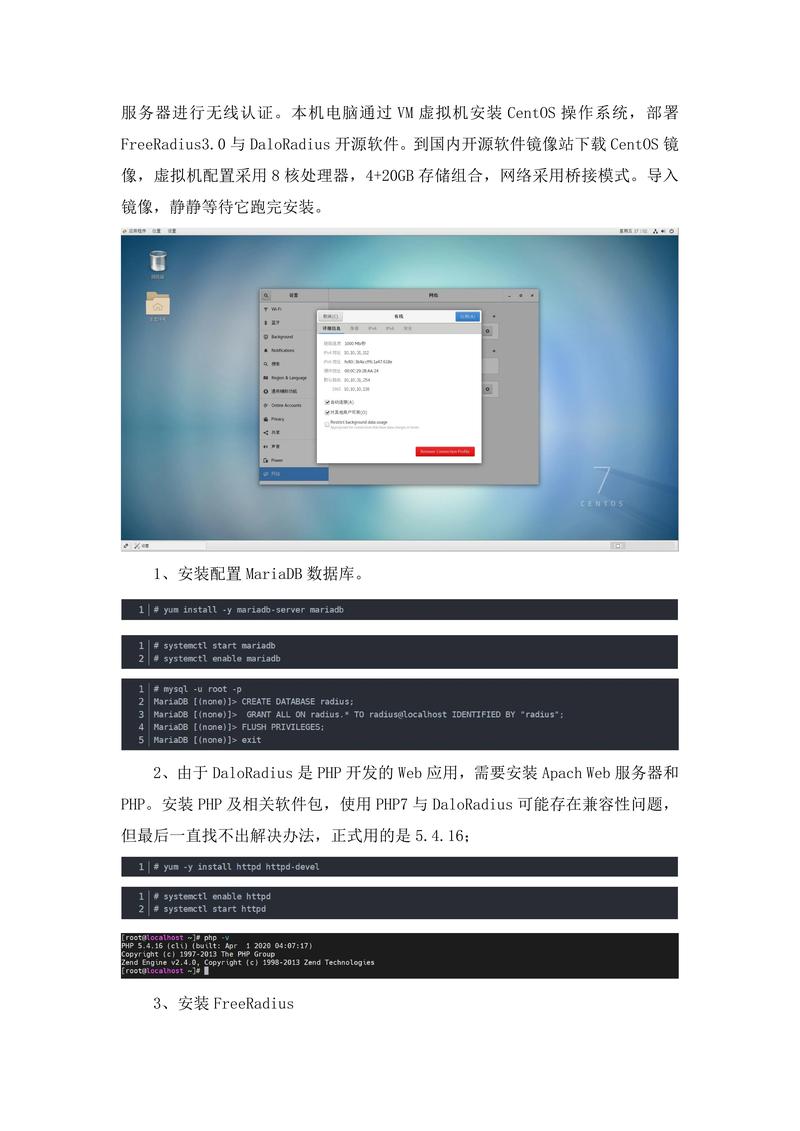
def extract_info:
response = requests.get
soup = BeautifulSoup
提取标题
title = soup.title.string if soup.title else No title found
提取描述
description = soup.find
description = description if description else No description found
提取关键词
keywords = soup.find
keywords = keywords if keywords else No keywords found
return {
‘title’: title,
‘description’: description,
‘keywords’: keywords
}
示例 URL
url = ‘https://example.com’
info = extract_info
“`
在这个示例中,我们使用了 `requests` 库来获取网页内容,并使用 `BeautifulSoup` 库来解析 html 内容。我们提取了网页的标题、描述和关键词,并将它们存储在一个字典中返回。你可以根据需要修改这个代码,以提取其他头部信息或进行其他操作。你有没有想过,在浏览网页的时候,那些链接里的信息其实可以轻松提取出来呢?比如,你有没有想过,用《uni-app》这个强大的框架,来提取URL中的头部公共信息?听起来是不是有点酷?那就让我们一起来看看,如何用类似知识星球Markdown文档内链接的简单信息提取代码,来玩转这个技能吧!
一、什么是《uni-app》?
首先,得先了解《uni-app》是个啥。简单来说,它是一个使用Vue.js开发所有前端应用的框架,可以编译到iOS、Android、H5、以及各种小程序等多个平台。这就意味着,你用一套代码,就能适配多个平台,是不是很神奇?
二、URL头部公共信息提取的意义
那么,为什么要提取URL的头部公共信息呢?举个例子,你可能需要根据URL的域名来判断用户访问的是哪个平台,或者根据URL的路径来获取特定的数据。这时候,提取头部公共信息就显得尤为重要了。
三、如何使用《uni-app》提取URL头部公共信息
接下来,我们就来聊聊如何使用《uni-app》来提取URL头部公共信息。这里,我给你提供一个简单的信息提取代码案例,让你轻松上手。
1. 引入uni.request
首先,你需要引入uni-app的请求模块uni.request。这个模块可以帮助你发送网络请求,获取数据。
“`javascript
import { request } from ‘uni-app’
2. 发送请求
你可以使用uni.request发送一个GET请求,获取URL中的信息。
“`javascript
request({
url: ‘https://www.example.com’, // 这里替换成你想要提取信息的URL
success: (res) => {
// 这里处理获取到的数据
console.log(res.data)
3. 提取头部公共信息
获取到数据后,你可以根据需要提取头部公共信息。以下是一个简单的示例:
“`javascript
request({
url: ‘https://www.example.com’,
success: (res) => {
const url = res.data.request.url
const hostname = url.split(‘/’)[2]
console.log(hostname) // 输出:www.example.com
在这个例子中,我们通过split方法将URL分割成数组,然后获取数组的第三个元素,即主机名。
四、类似知识星球Markdown文档内链接的简单信息提取代码
如果你想要提取类似知识星球Markdown文档内链接的简单信息,可以参考以下代码:
“`javascript
function extractMarkdownLinkInfo(markdownText) {
const regex = /!\\[(.?)\\]\\((.?)\\)/g
let match
let links = []
while ((match = regex.exec(markdownText)) !== null) {
links.push({
text: match[1],
url: match[2]
})
return links
const markdownText = ‘’
const extractedLinks = extractMarkdownLinkInfo(markdownText)
console.log(extractedLinks) // 输出:[ { text: ‘示例图片’, url: ‘https://example.com/image.png’ } ]
在这个例子中,我们使用正则表达式匹配Markdown文档中的图片链接,并提取出链接文本和URL。
五、
通过以上内容,相信你已经学会了如何使用《uni-app》提取URL头部公共信息,以及如何提取类似知识星球Markdown文档内链接的简单信息。这些技能在开发过程中非常有用,希望你能灵活运用,为你的项目增添更多亮点!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...
